C1 Supervised Machine Learning: Regression and Classification
C1_W1 Introduction to Machine Learning
C1_W1_M1 Supervised vs Unsuperverside Machine Learning
C1_W1_M1_1 What is machine learning?
Field of study that gives computers the ability learn without being explicitly pogrammed -- Arthur Samuel
Supervised vs Unsupervised
C1_W1_M1_2 Supervised Learning: Regression Algorithms
learn x to y or input to output mappings
| Input (x) | Output (Y) | Application |
|---|---|---|
| spam? (0/1) | spam filtering | |
| audio | text transcripts | speech recognition |
| Enlish | Spanish | machine translation |
| ad, user | click? (0/1) | online advertising |
| image, radar | position of other cars | self-driving car |
| image of phone | defect? (0/1) | visual inspection |
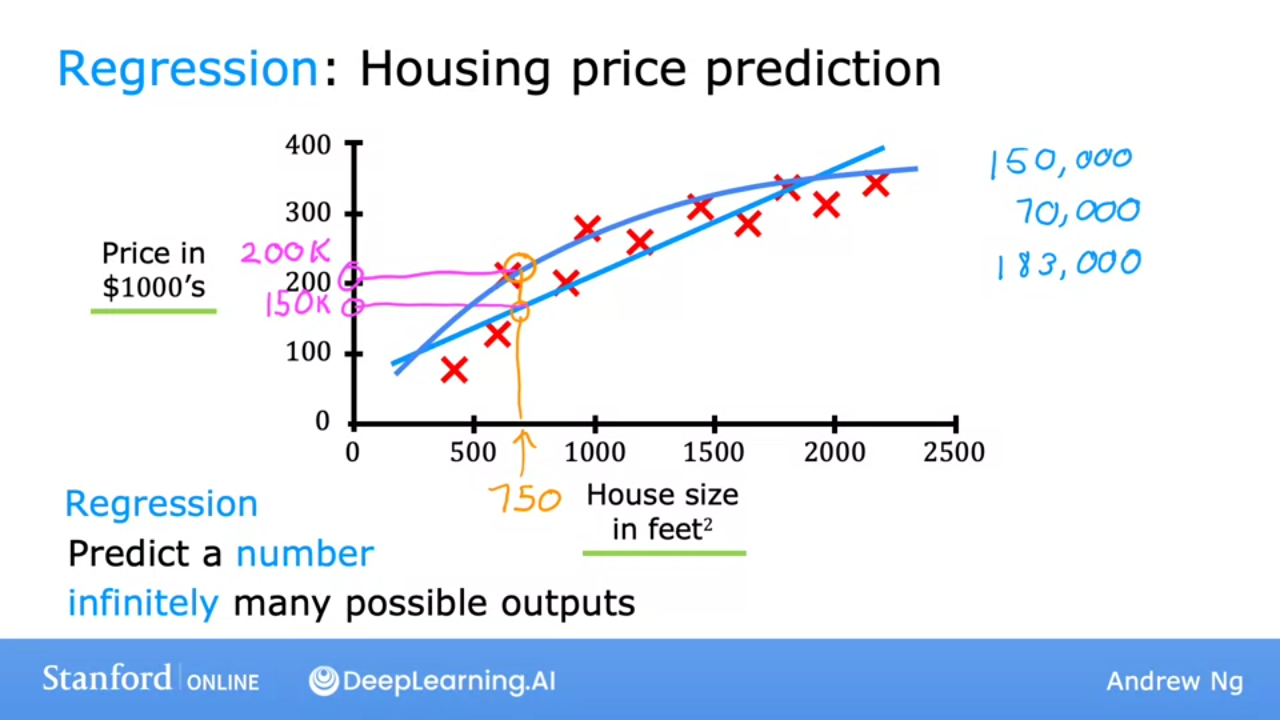
- Use different algorithms to predict price of house based on data
C1_W1_M1_3 Supervised Learning: Classification
Regression attempts to predict ininite possible results
Classification predicts categories ie from limited possible results
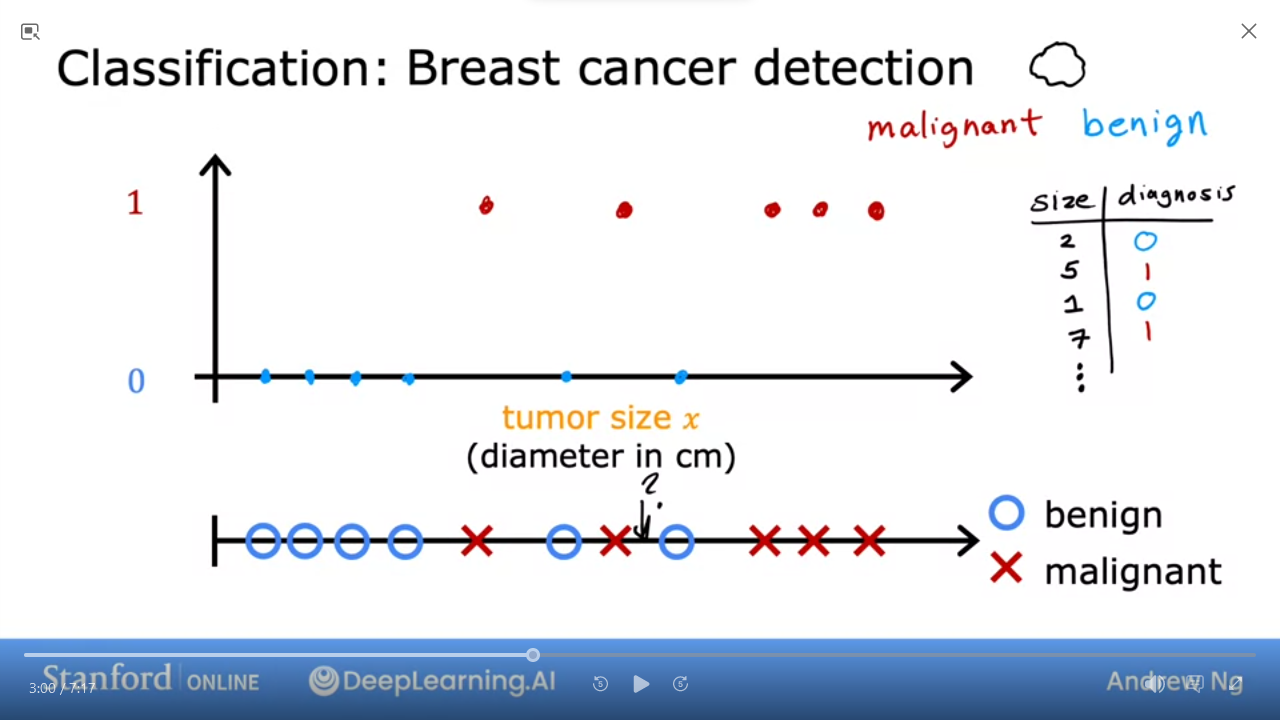
- e.g. Breast cancer detection
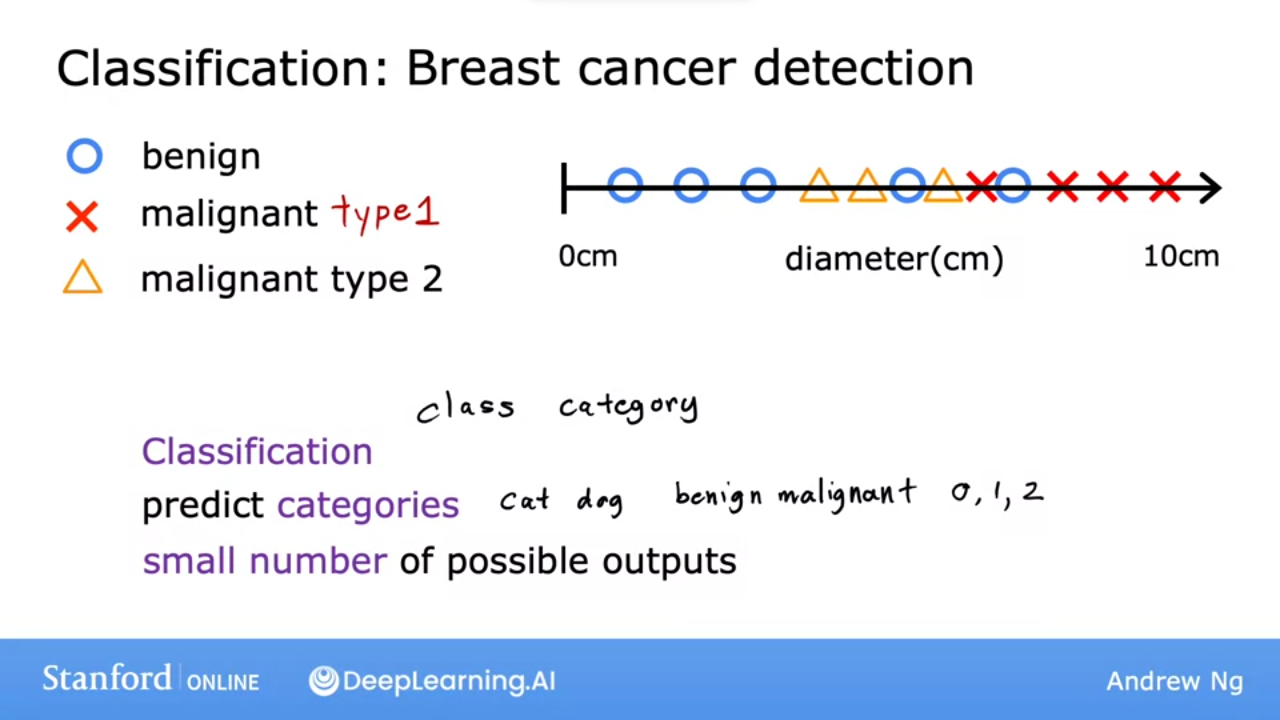
- we can have multiple outputs
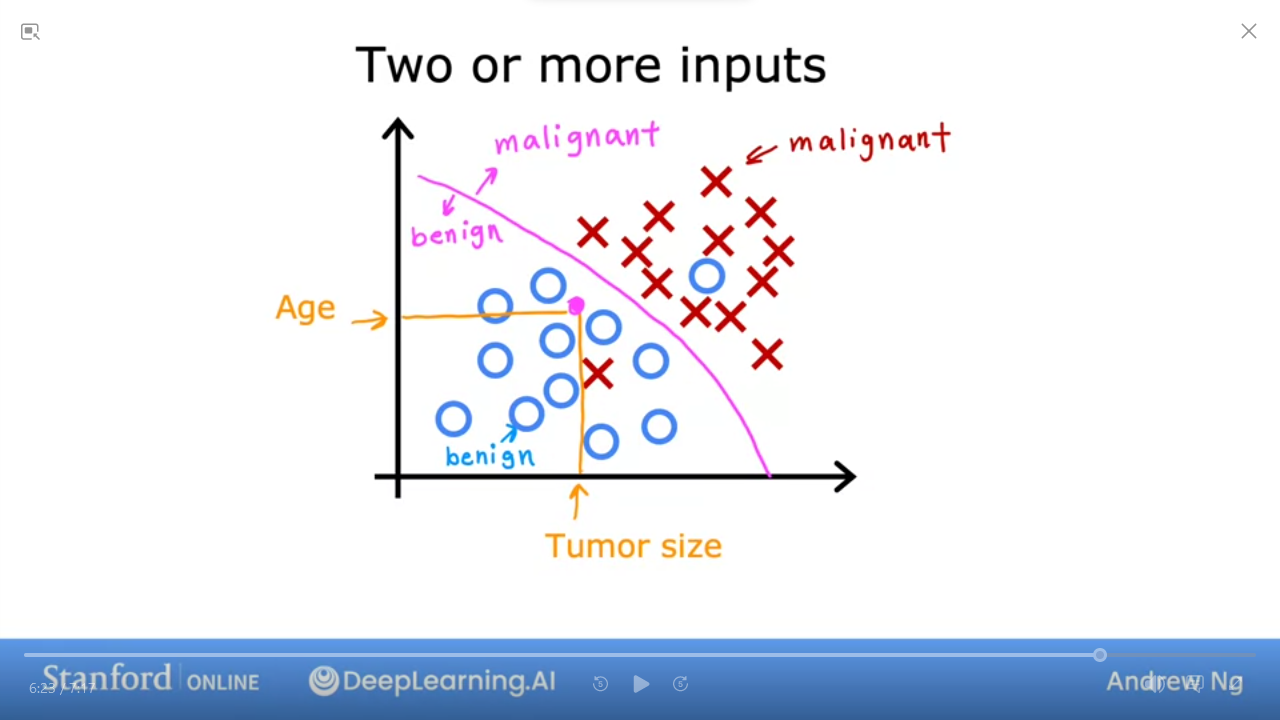
- we can draw a boundary line to separate our output
Supervised Learning
| Regression | Classification | |
|---|---|---|
| Predicts | numbers | categories |
| Outputs | infinite | limited |
C1_W1_M1_4 Unsupervised Learning
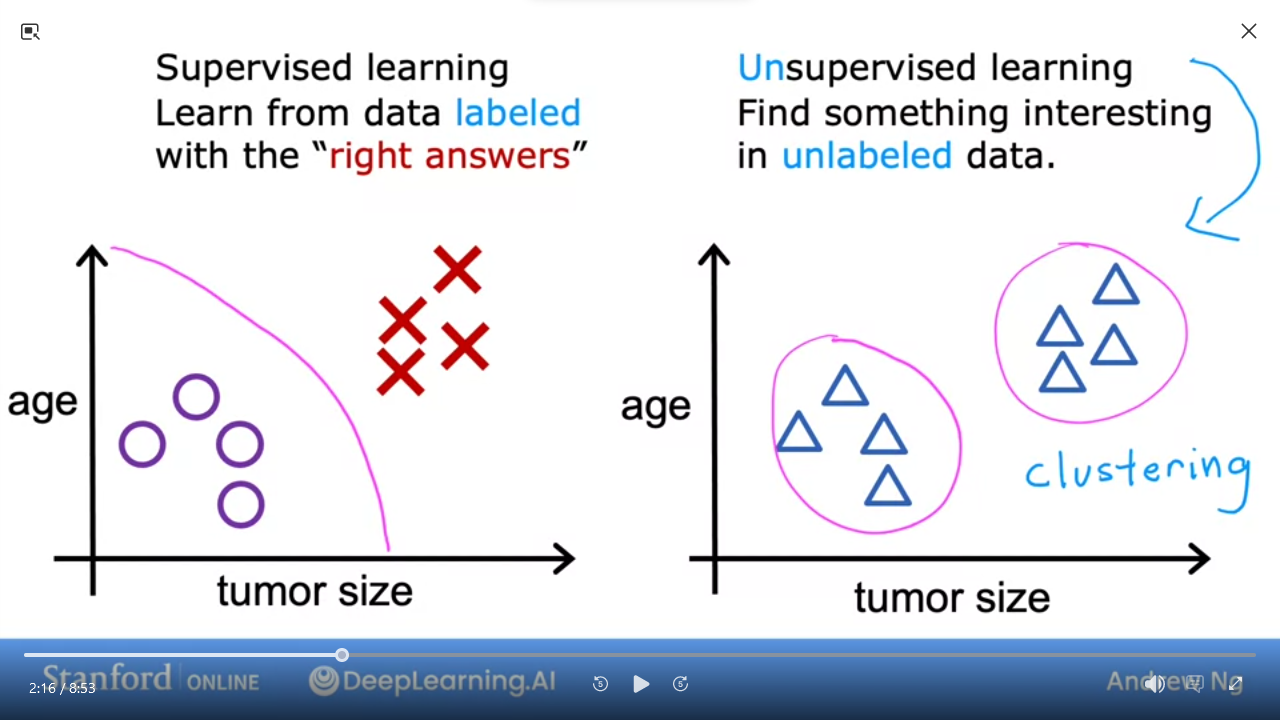
- With unsupervised we don't have predetermined expected output
- we're trying to find structure in the pattern
- in this example it's
clustering - e.g. Google News will "cluster" news related to pandas given a specific article about panda/birth/twin/zoo

- e.g. given set of individual genes, "cluster" similar genes
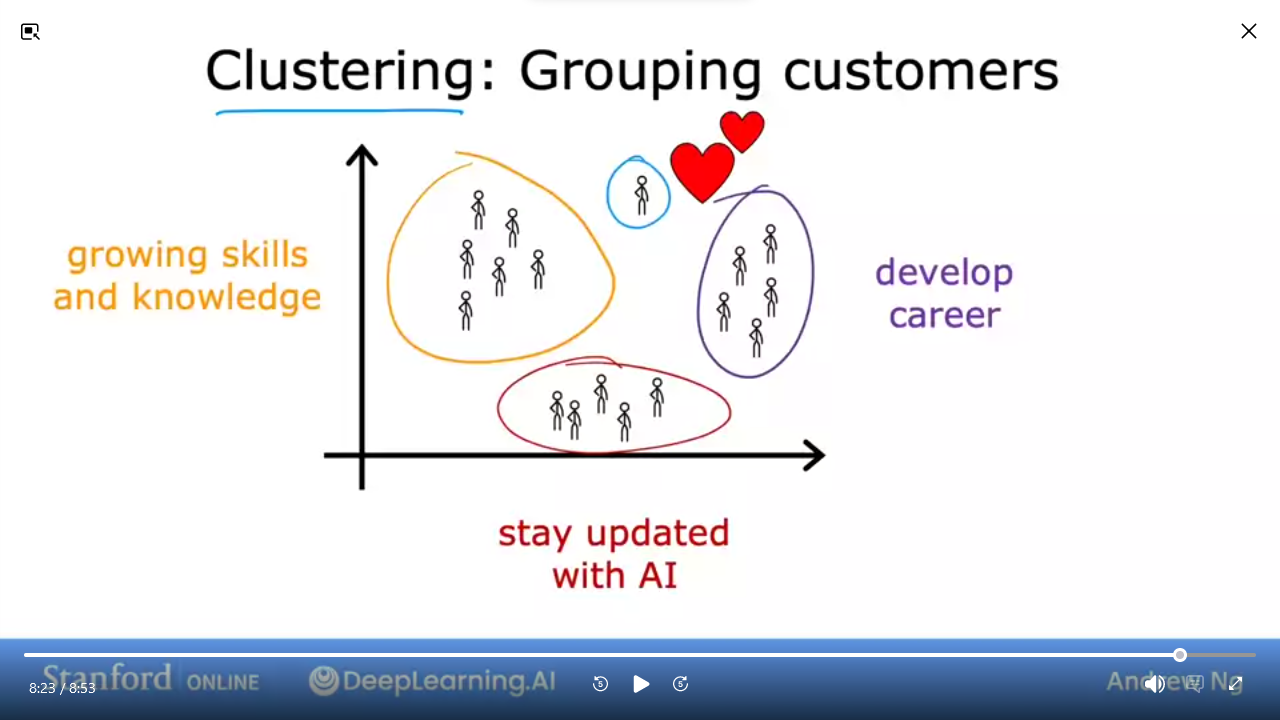
- e.g. how deeplearning.ai categorizes their learners
Unsupervised Learning: Data only comes with inputs x, but not output labels y. Algorithm has to find structure in the data
Clustering: Group similar data points togetherAnomaly Detection: Find unusual data pointsDimensionality Reduction: Compress data using fewer numbers
Question: Of the following examples, which would you address using an unsupervised learning algorithm?
(Check all that apply.)
- [ ] Given a set of news articles found on the web, group them into sets of articles about the same stories.
- [ ] Given email labeled as spam/not spam, learn a spam filter.
- [ ] Given a database of customer data, automatically discover market segments and group customers into different market segments.
- [ ] Given a dataset of patients diagnosed as either having diabetes or not, learn to classify new patients as having diabetes or not.
Lab 01: Python and Jupyter Notebooks
Quiz: Supervised vs Unsupervised Learning
Which are the two common types of supervised learning (choose two)
- [ ] Classificaiton
- [ ] Regression
- [ ] Clustering
Which of these is a type of unsupervised learning?
- [ ] Clustering
- [ ] Regression
- [ ] Classification
C1_W1_M2 Regression Model
C1_W1_M2_1 Linear regression model part 1
Linear Regression Model => a Supervised Learning Model that simply puts a line through a dataset
- most commonly used model
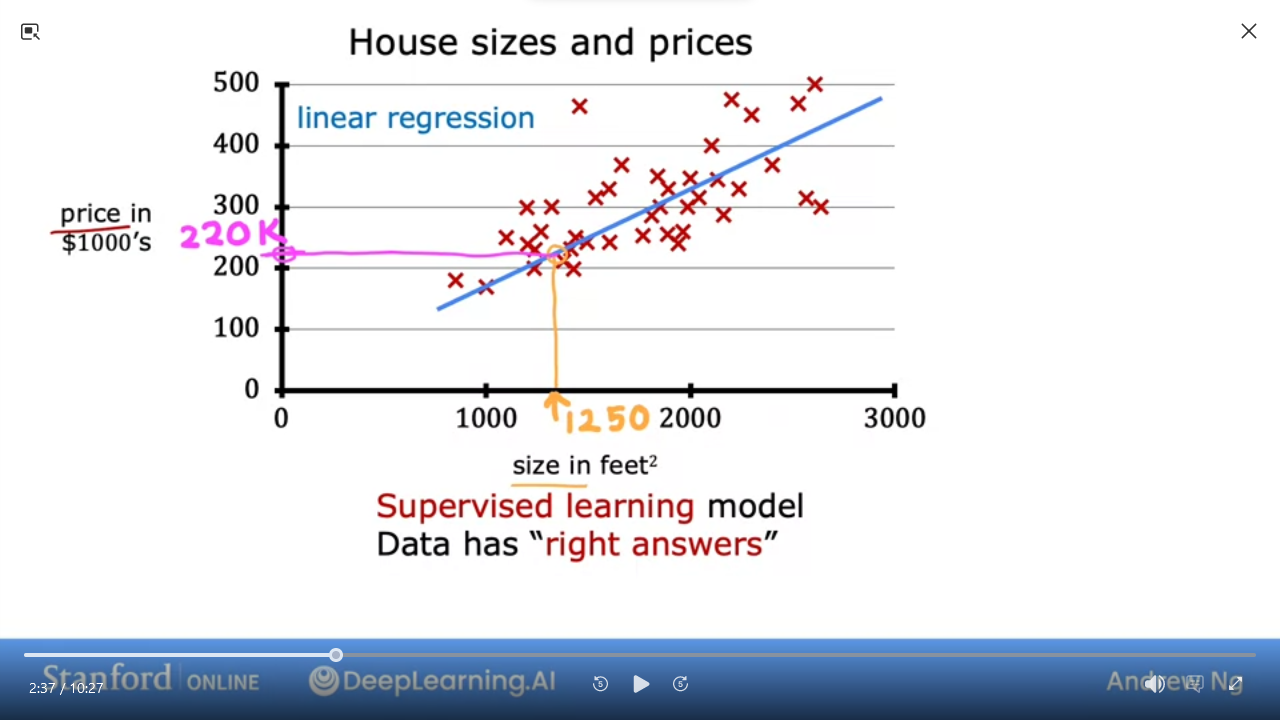
- e.g. Finding the right house price based on dataset of houses by sq ft.
| Terminology | |
|---|---|
| Training Set | data used to train the model |
| x | input variable or feature |
| y | output variable or target |
| m | number of training examples |
| (x,y) | single training example |
| (xⁱ,yⁱ) | i-th training example |
C1_W1_M2_2 Linear regression model part 2
f is a linear function with one variable
- $ f_{w,b}(x) = wx + b $ is equivalent to
- $ f(x) = wx + b $
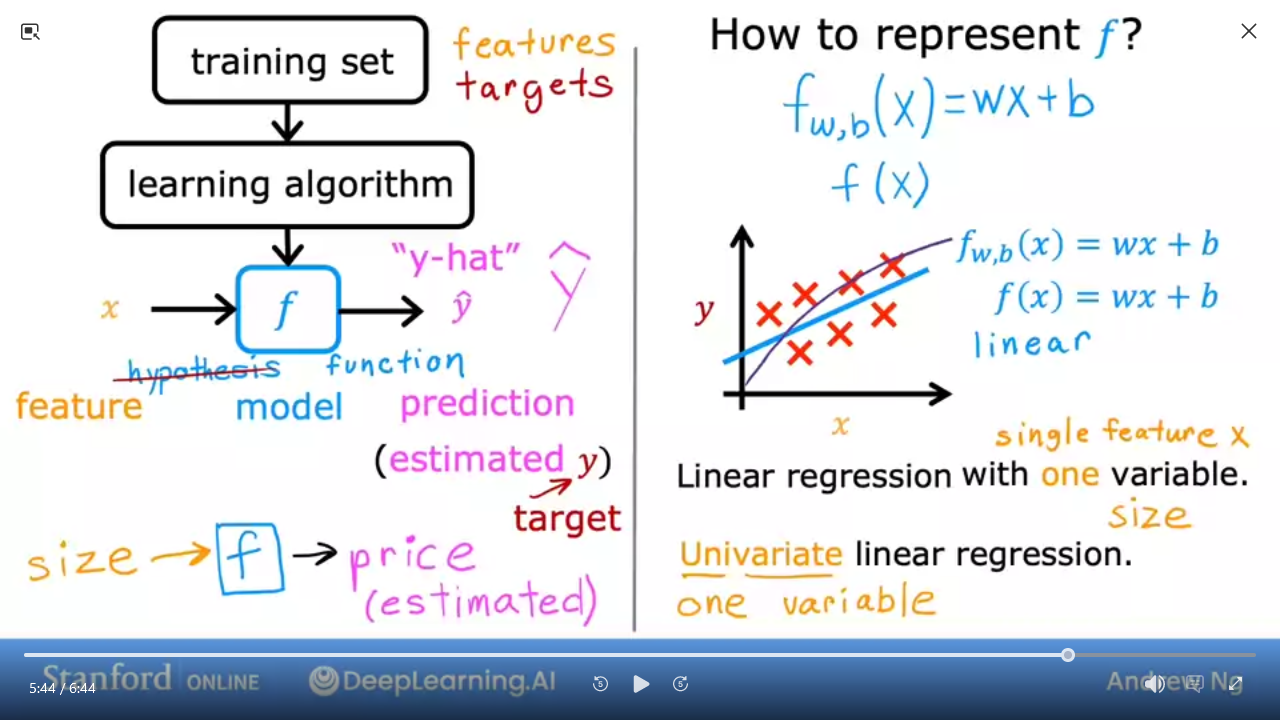
-
Univariatelinear regression => one variable
Lab 02: Model representation
Here is a summary of some of the notation you will encounter.
| General Notation | Python (if applicable) | Description |
|---|---|---|
| $ a $ | scalar, non bold | |
| $ \mathbf{a} $ | vector, bold | |
| Regression | ||
| $ \mathbf{x} $ | x_train |
Training Example feature values (in this lab - Size (1000 sqft)) |
| $ \mathbf{y} $ | y_train |
Training Example targets (in this lab Price (1000s of dollars)) |
| $ x^{(i)}$, $y^{(i)} $ |
x_i, y_i
|
$ i_{th} $ Training Example |
| m | m |
Number of training examples |
| $ w $ | w |
parameter: weight |
| $ b $ | b |
parameter: bias |
| $ f_{w,b}(x^{(i)}) $ | f_wb |
The result of the model evaluation at $ x^{(i)} $ parameterized by $ w,b $: $ f_{w,b}(x^{(i)}) = wx^{(i)}+b $ |
Code
-
NumPy, a popular library for scientific computing -
Matplotlib, a popular library for plotting data-
scatter()to plot on a graph-
markerfor symbol to use -
cfor color
-
-
C1_W1_M2_4 Cost function formula
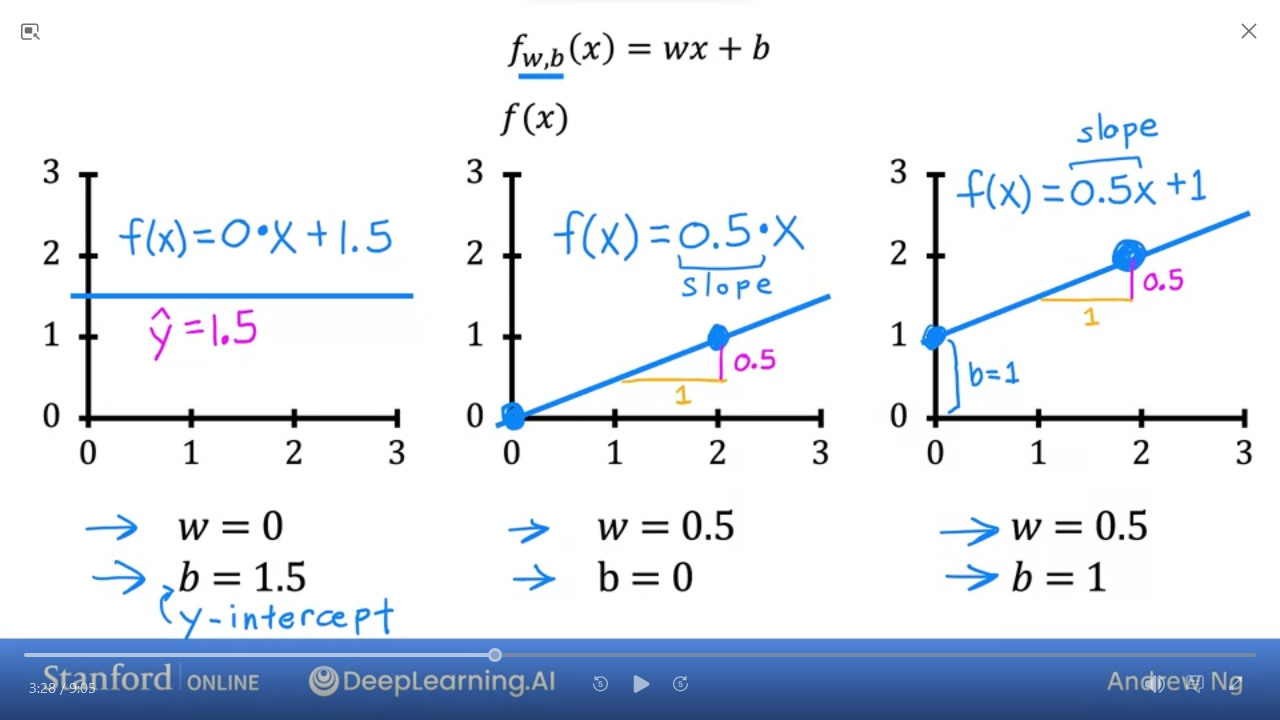
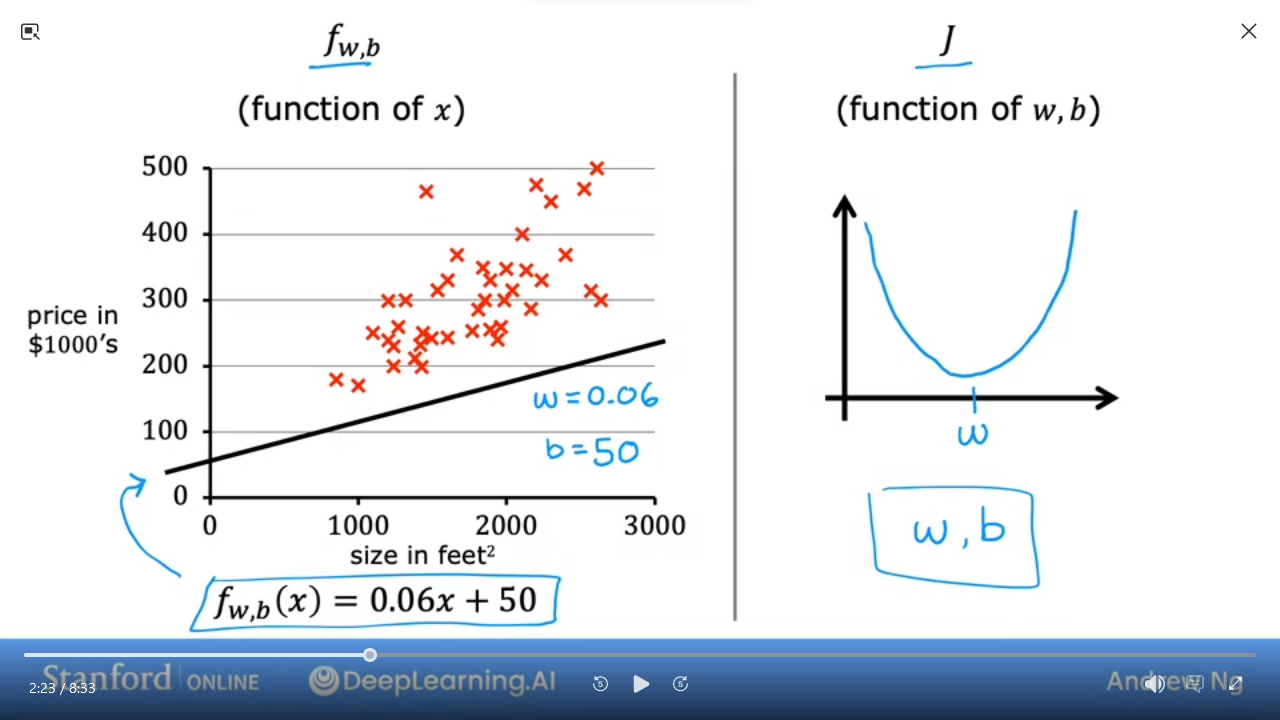
- We can play with
w&bto find the best fit line

- 1st step to implement linear function is to define
Cost Function - Given $ f_{w,b}(x) = wx + b $ where
wis theslopeandbis they-intercept -
Cost functiontakes predicted $ \hat{y} $ and compares toy - ie
error= $ \hat{y} - y $ - $ \sum\limits_{i=1}^{m} (\hat{y}^{(i)} - y^{(i)})^{2} $
- where
mis the number of training examples
- where
- Dividing by
2mmakes the calculation neater $ \frac{1}{2m} \sum\limits_{i=1}^{m} (\hat{y}^{(i)} - y^{(i)})^{2} $ - Also known as
squared error cost function$ J_{(w,b)} = \frac{1}{2m} \sum\limits_{i=1}^{m} (\hat{y}^{(i)} - y^{(i)})^{2} $ - Which can be rewritten as $ J_{(w,b)} = \frac{1}{2m} \sum\limits_{i=1}^{m} (f_{w,b}(x^{(i)}) - y^{(i)})^{2} $
- Remember we want to find values of
w,bwhere $ \hat{y}^{(i)} $ is close to $ y^{(i)} $ for all $ (x^{(i)}, y^{(i)}) $
Question: Which of these parameters of the model that can be adjusted?
- $ w $ and $ b $
- $ f_{w,b} $
- $ w $ only, because we should choose $ b = 0 $
- $ \hat{y} $
C1_W1_M2_5 Cost Function Intuition
To get a sense of how to minimize $ J $ we can use a simplified model
| simplified | ||
|---|---|---|
| model | $ f_{w,b}(x) = wx + b` | $ f_{w}(x) = wx` by setting $ b=0 $ |
| parameters | $ w $, $ b $ | $ w $ |
| cost function | $ J_{(w,b)} = \frac{1}{2m} \sum\limits_{i=1}^{m} (f_{w,b}(x^{(i)}) - y^{(i)})^{2} $ | $ J_{(w)} = \frac{1}{2m} \sum\limits_{i=1}^{m} (f_{w}(x^{(i)}) - y^{(i)})^{2} $ |
| goal | we want to minimize $ J_{(w,b)} $ | we want to minimize $ J_{(w)} $ |
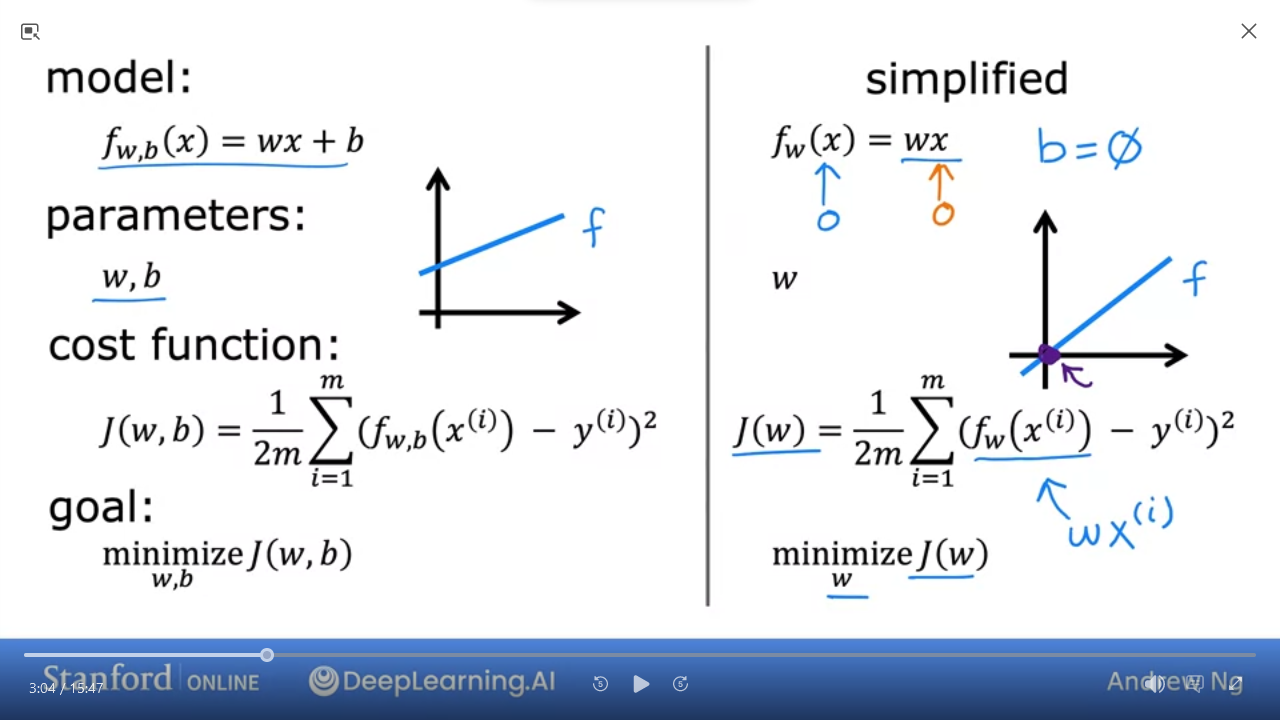
- we can use simplified function to find the best fit line
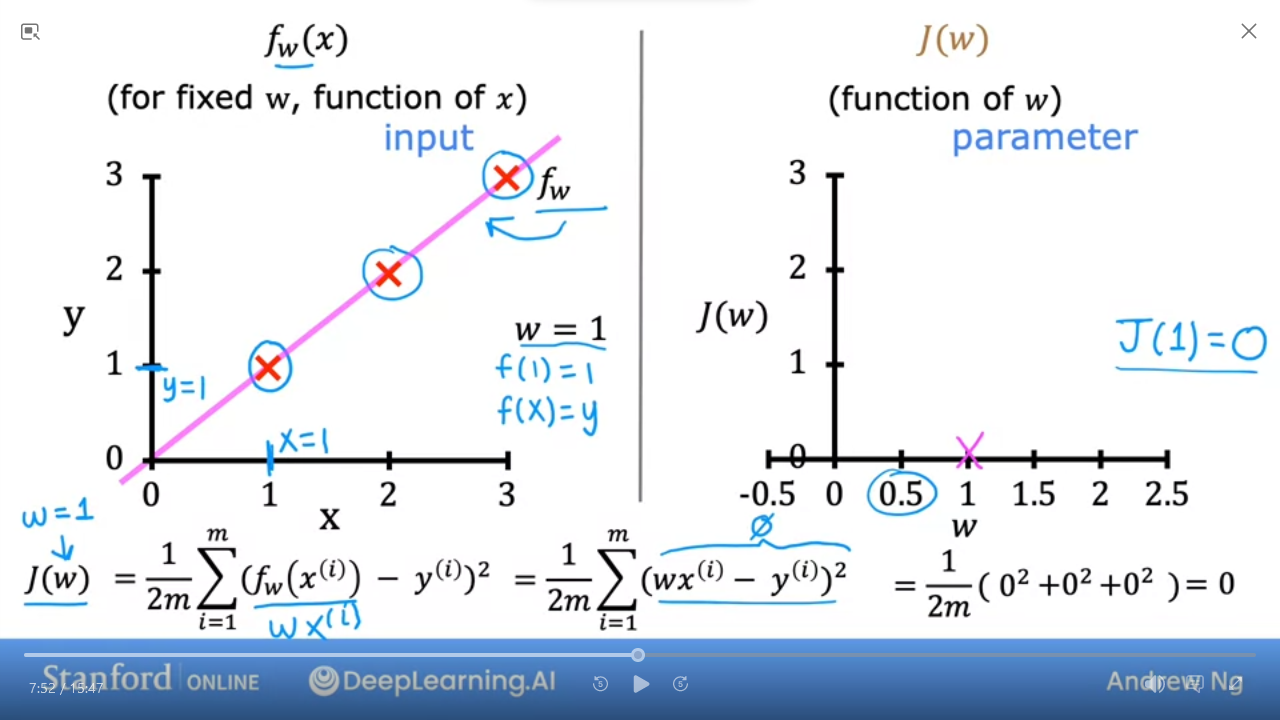
- the 2nd graph shows that when $ w = 1 $ then $ J(1) = 0 $
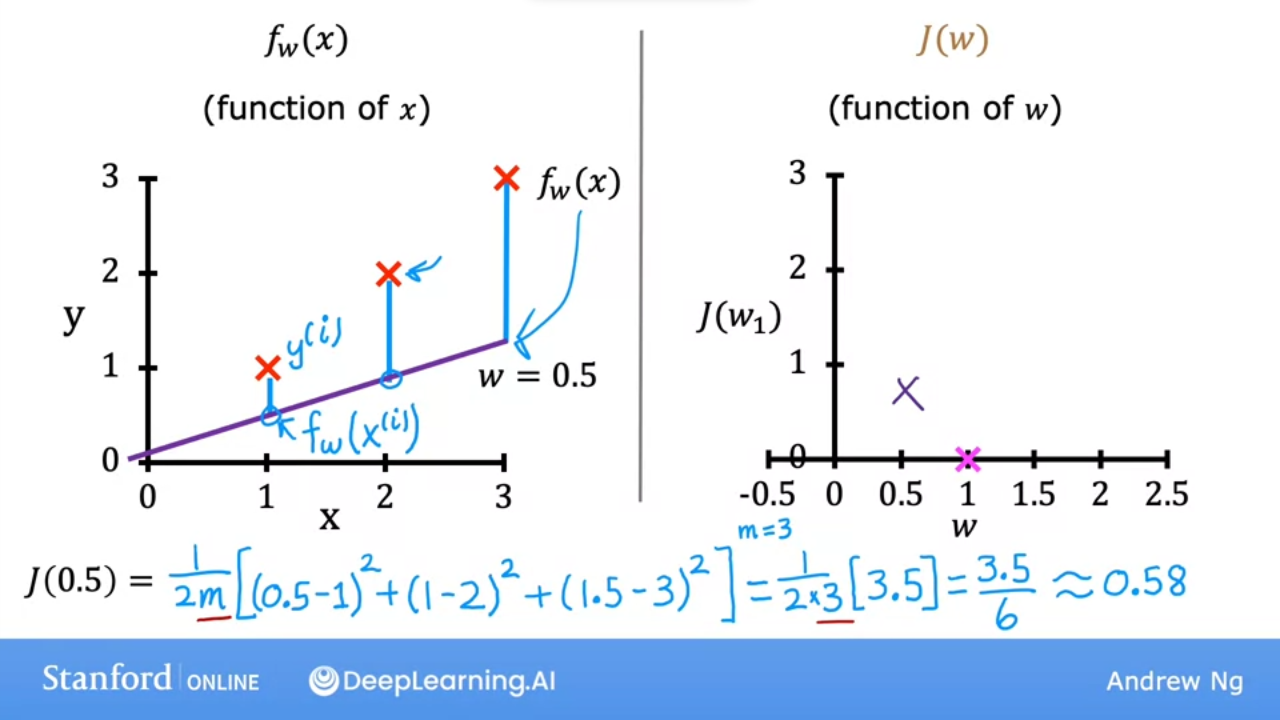
- the 2nd graph shows that when $ w = 0.5 $ then $ J(0.5) ~= 0.58 $
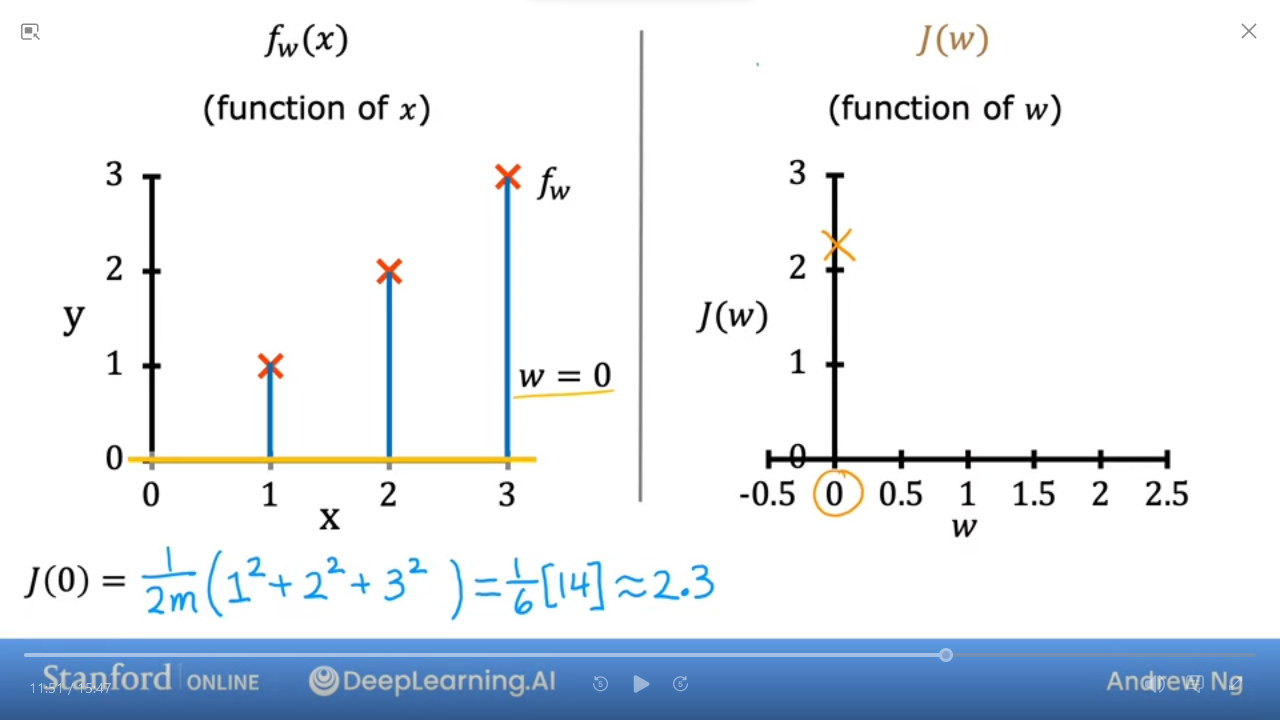
- the 2nd graph shows that when $ w = 0 $ then $ J(0) ~= 2.33 $
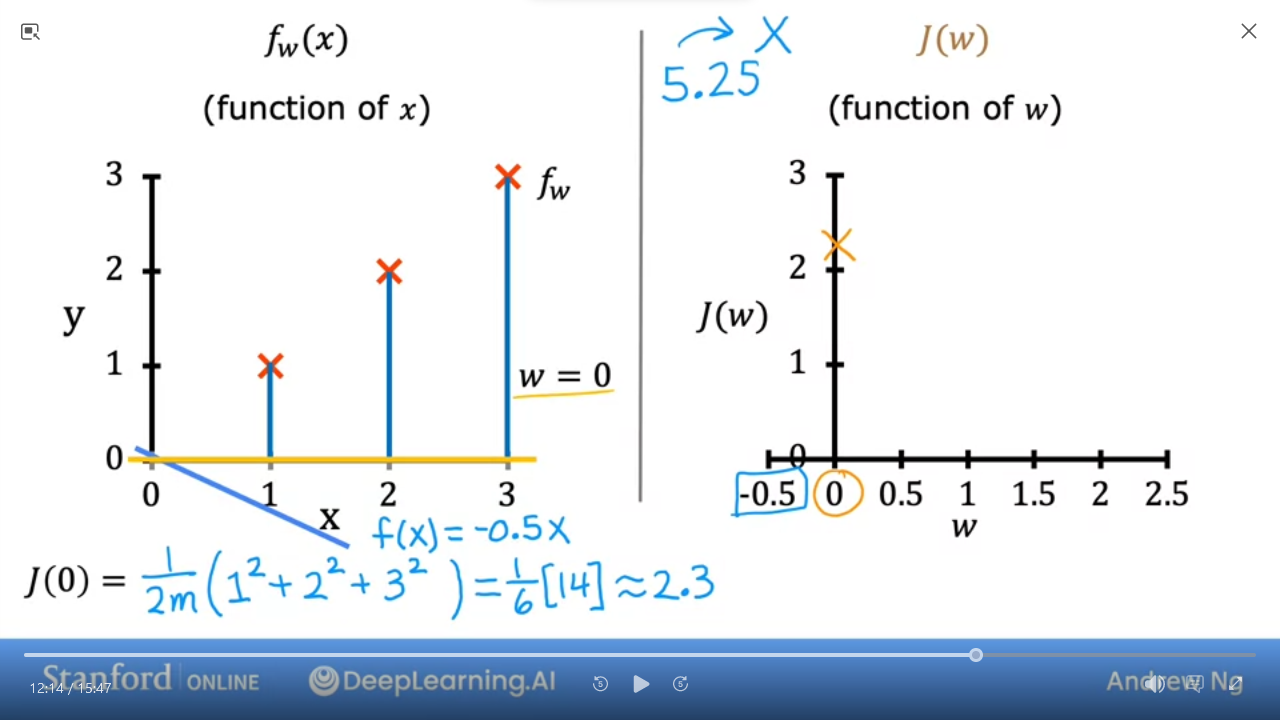
- We can do this calculation for various $ w $ even negative numbers
- when $ w = -0.5 $ then $ J(-0.5) ~= 5.25 $
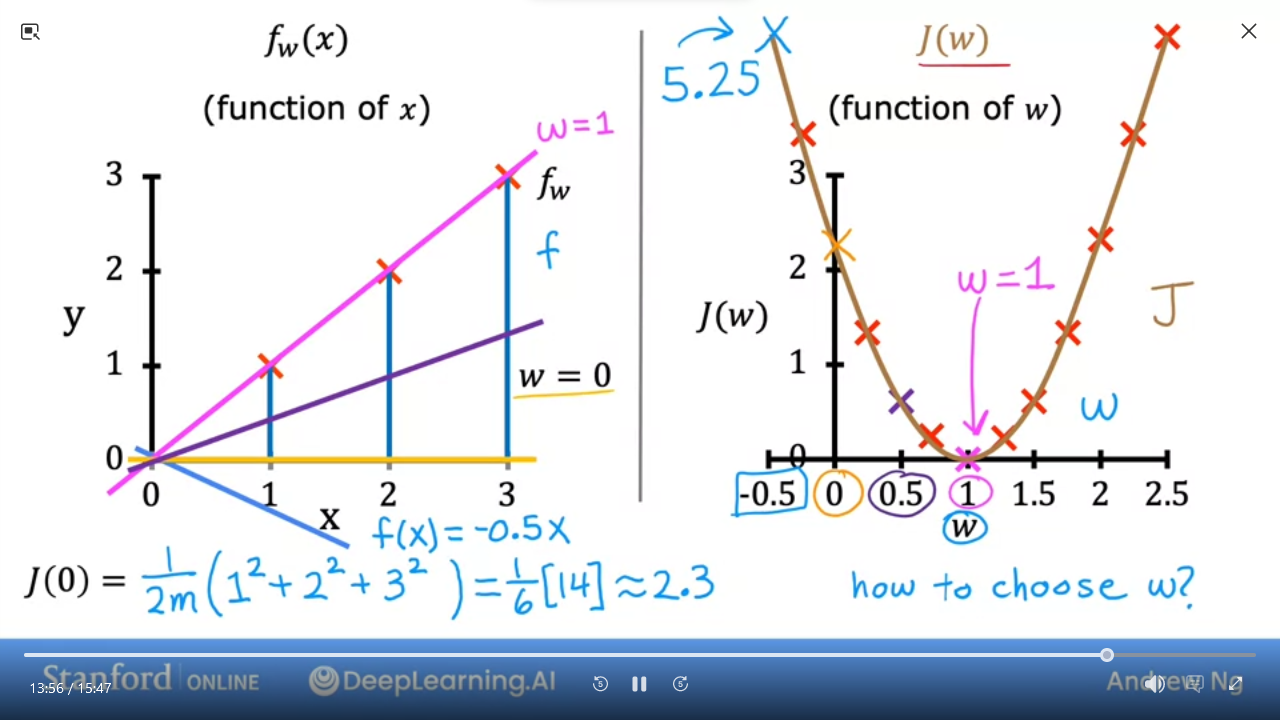
- We can plot various values for
wand get a graph (on the right) - As we can see the cost function with $ w = 1 $ is the best fit line for this data
The goal of linear regression is to find the values of $ w,b $ that allows us to minimize $ J_{(w,b)} $
C1_W1_M2_6 Visualizing the cost function
| model | $ f_{w,b}(x) = wx + b $``$ |
| parameters | $ w $, $ b $ |
| cost function | $ J_{(w,b)} = \frac{1}{2m} \sum\limits_{i=1}^{m} (f_{w,b}(x^{(i)}) - y^{(i)})^{2} $ |
| goal | minimize $ J_{(w,b)} $ |
- When we only have w, then we can plot
Jvswin 2-dimensions
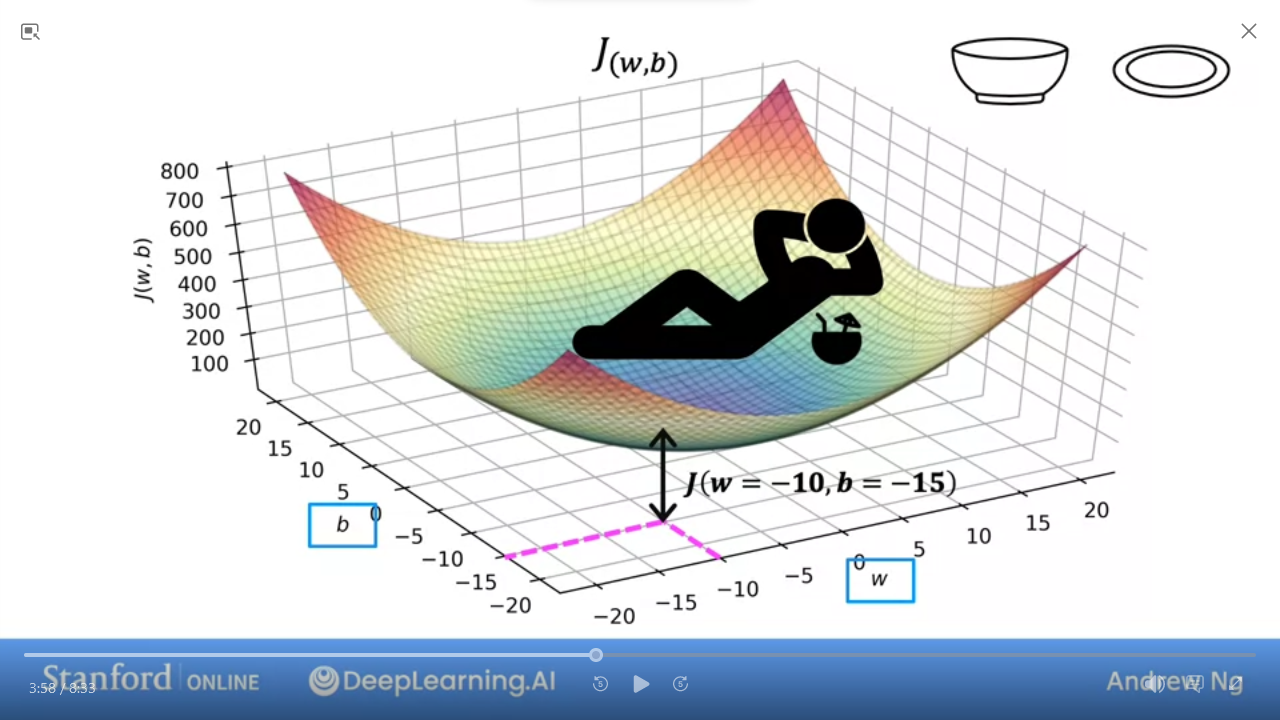
- However, when we add
bthen it's 3-dimensional - The value of
Jis the height
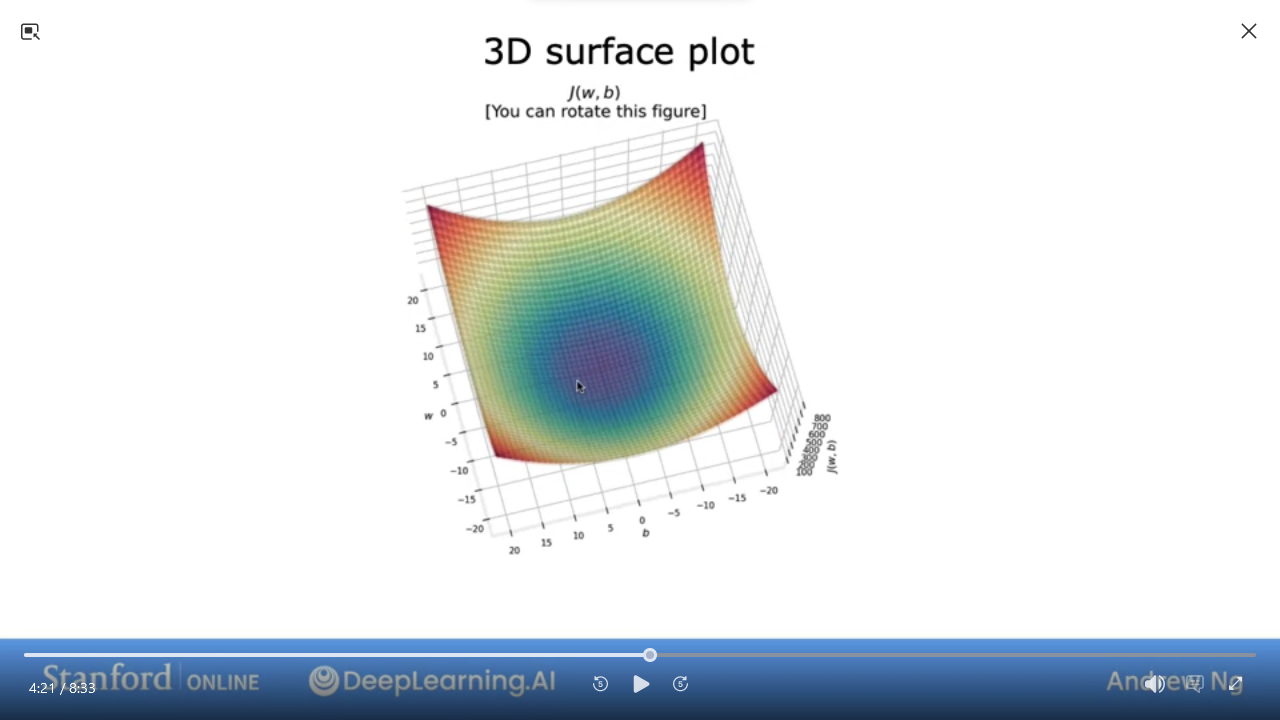
- this is easier to visualize as a
contour plot
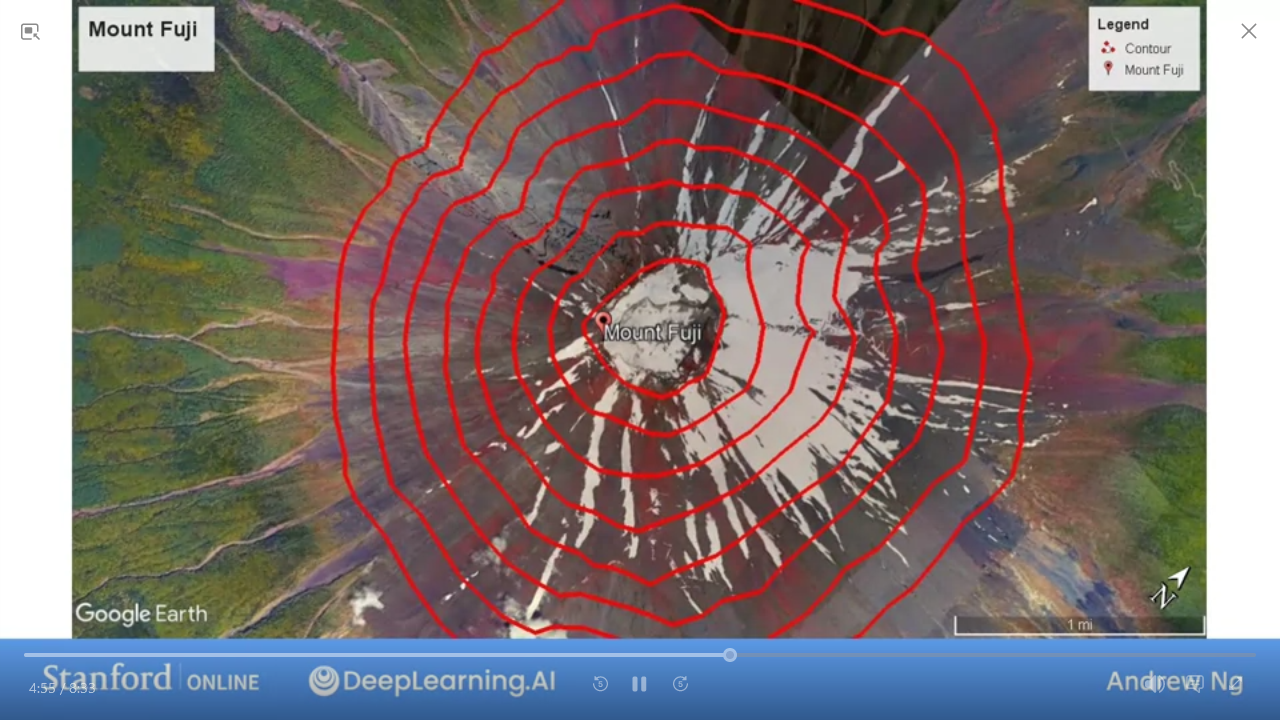
- Same as used to visualize height of mountains
- take a horizontal slice which gives you the same
Jfor givenw,b - the center of the contour is the minimum
-
Countour allows us to visualize the 3-D
Jin 2-D
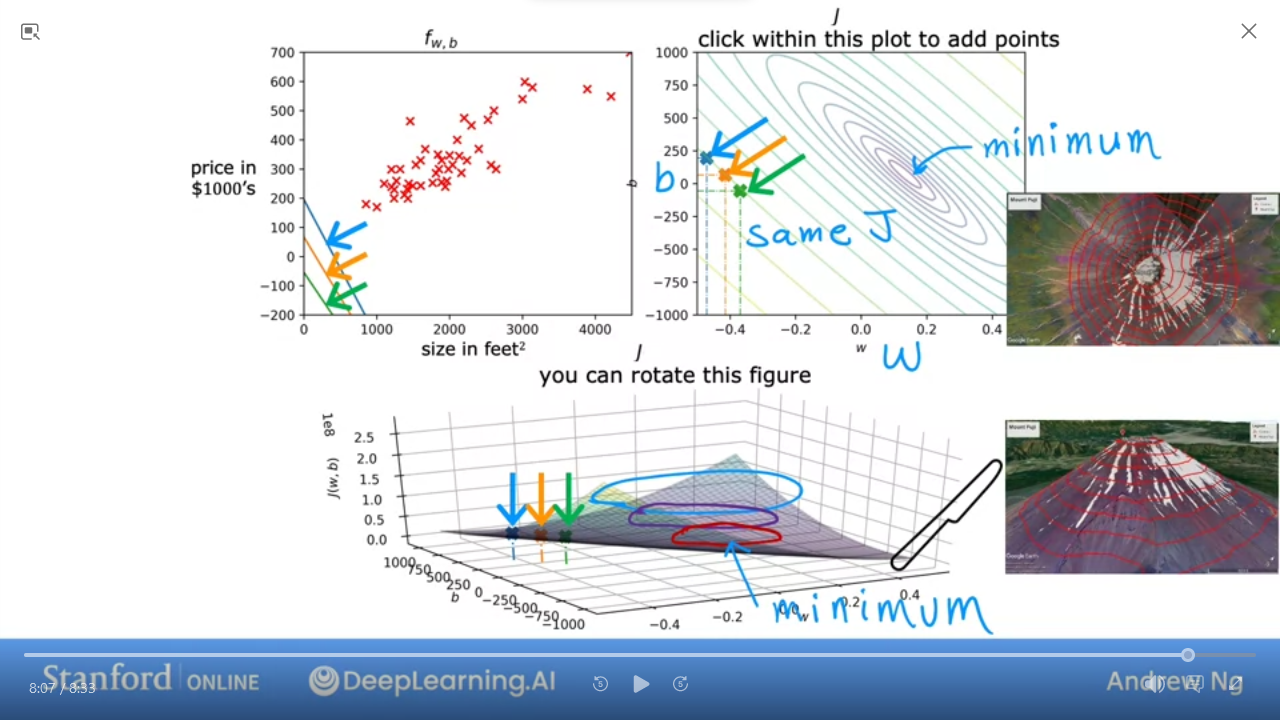
C1_W1_M2_7 Visualization examples
Here are some examples of J
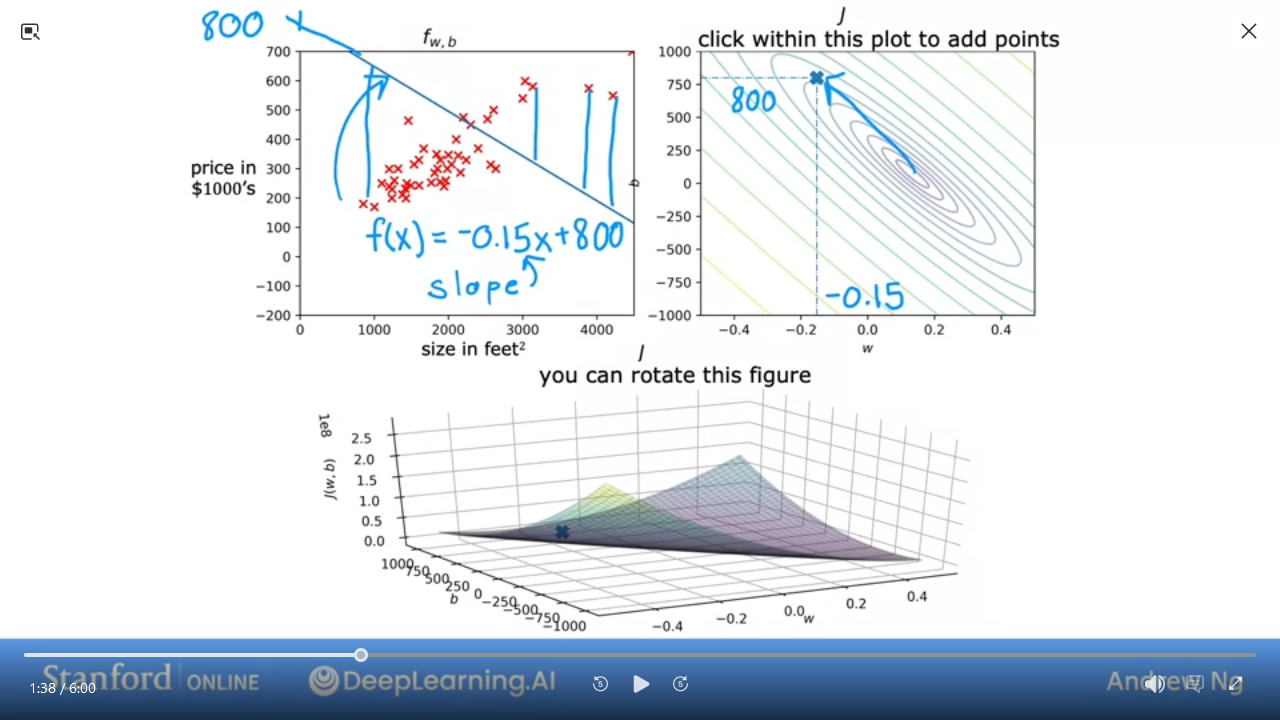
- We can see this is a pretty bad
J
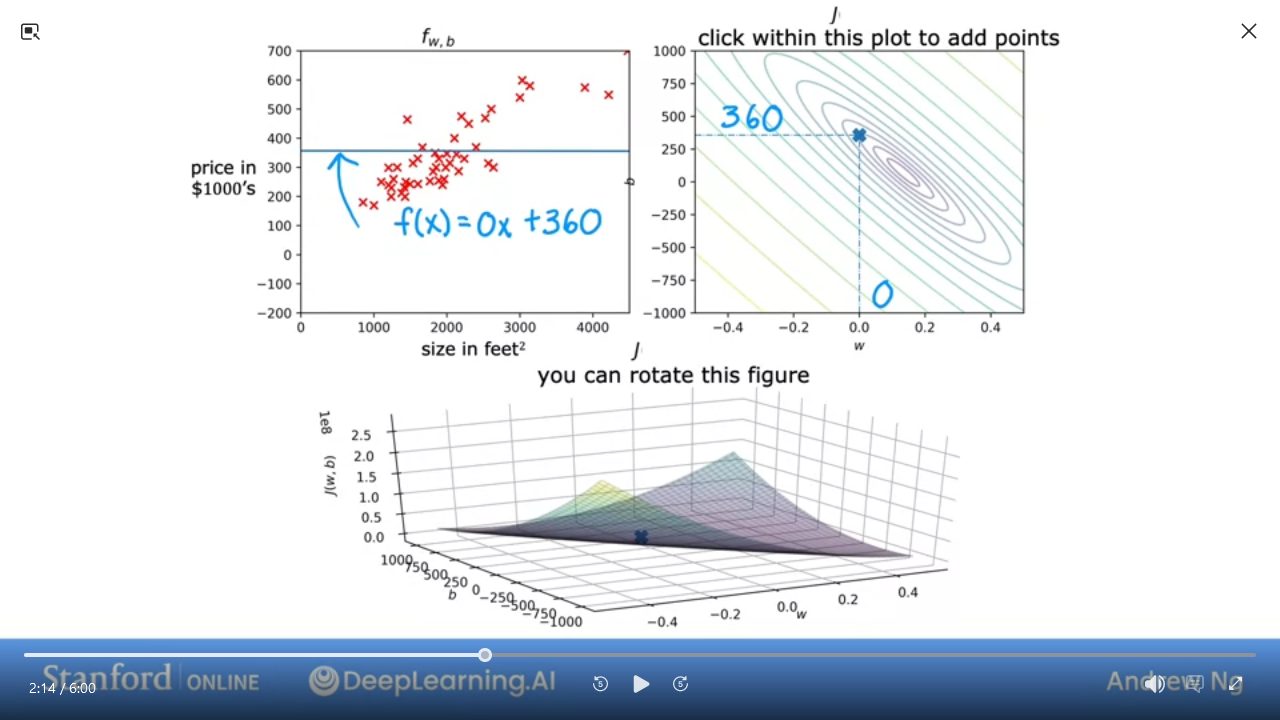
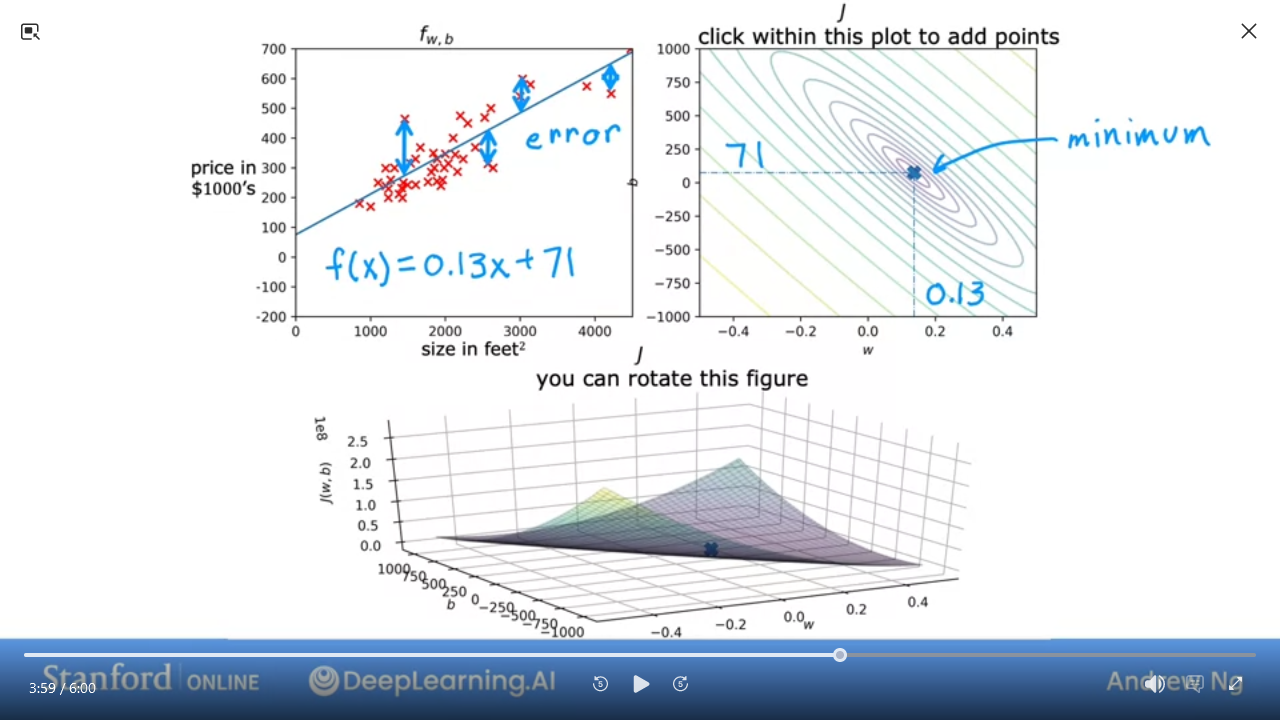
- This is pretty good and close to minimal (but not quite perfect)
In the next lab, you can click on different points on the contour to view the cost function on the graph
Gradient Descentis an algorithm to train linear regression and other complex models
Lab 03: Cost function
- Coursera Jupyter: Cost Function
-
Local: Cost Function
from lab_utils_uni import plt_intuition, plt_stationary, plt_update_onclick, soup_bowl
Quiz: Regression Model
- Which of the following are the inputs, or features, that are fed into the model and with which the model is expected to make a prediciton?
- [ ] $ m $
- [ ] $ w $ and $ b $
- [ ] $ (x,y) $
- [ ] $ x $
- For linear regression, if you find parameters $ w $ and $ b $ so that $ J_{(w,b)} $ is very close to zero, what can you conclude?
- [ ] The selected values of the parameters $ w, b $ cause the algorithm to fit the training set really well
- [ ] This is never possible. There must be a bug in the code
- [ ] The selected values of the parameters $ w, b $ cause the algorithm to fit the training set really poorly
Ans
4, 1C1_W1_M3 Train the model with gradient descent
C1_W1_M3_1 Gradient descent
Want a systematic way to find values of $ w,b $ that allows us to easily find smallest $ J $
Gradient Descent is an algorithm used for any function, not just in linear
regression but also in advanced neural network models

- start with some $ w,b $ e.g. $ (0,0) $
- keep changing $ w,b $ to reduce $ J(w,b) $
- until we settle at or near a minimume

- Example of a more comples $ J $
- not a squared error cost
- not linear regression
- we want to get to the lowest point in this topography
- pick a direction and take a step that is slightly lower
- repeat until you're at lowest point
- However, depending on starting point and direction, you will end up at a different "lowest point"
- Known as
local mimina
- Known as
local minimamay not be the true lowest point
C1_W1_M3_2 Implementing gradient descent

- The
Gradient Descentalgorithm - $ w = w - \alpha \frac{\partial}{\partial w} J_{(w,b)} $
- $ \alpha $ ==
learning rate. ie How "big a step" you take down the hill - $ \frac{\partial}{\partial w} J_{(w,b)} $ ==
derivative. ie which direction
- $ \alpha $ ==
- $ b = b - \alpha \frac{\partial}{\partial b} J_{(w,b)} $
- We repeat these 2 steps for $ w,b $ until the algorithm converges
- ie each subsequent step doesn't change the value
- We want to simultaneously update w and b at each step
-
tmp_w =$ w - \alpha \frac{\partial}{\partial w} J_{(w,b)} $ -
tmp_b =$ b - \alpha \frac{\partial}{\partial b} J_{(w,b)} $ w = tmp_w && b = tmp_b
-
C1_W1_M3_3 Gradient descent intuition

- We want to find minimum
w,b
$$ \begin{aligned} \text{repeat until convergence {} \ &w = w - \alpha \frac{\partial}{\partial w} J_{(w,b)}\ &b = b - \alpha \frac{\partial}{\partial b} J_{(w,b)}\ } \end{aligned} $$
- Starting with finding
min wwe can simplify to just $ J(w) $ - Gradient descent with $ w = w - \alpha \frac{\partial}{\partial w} J_{(w)} $
- minimize cost by adjusting just
w: $ \min J(w) $

- Recall previous example where we set
b = 0 - Initialize
wat a random location - $ \frac{\partial}{\partial w} J(w) $ is the slope
- we want to find slopes that take us to minimum w
- In the first case, we get $ w - \alpha (positive number) $ which is the correct direction
- However (2nd graph), slope is negative, and therefore also in the correct direction
C1_W1_M3_4 Learning rate

- $ \alpha $ is the learning rate ie how big a step to take
- If too small then you take small steps and will take a long time to find minimum
- If too big then you might miss true minimum ie diverge instead of converge

- If you're already at local minimum...
-
slope = 0and therefore $ \frac{\partial}{\partial w} J(w) = 0 $- ie
w = w * 0 - further steps will bring you back here
- ie

- As we get closer to local minimum, gradient descent (derivative function) will automatically take smaller steps
C1_W1_M3_5 Gradient descent for linear regression

- linear regression model $ f_{w,b}(x) = wx + b $
- cost function $ J_{(w,b)} = \frac{1}{2m} \sum\limits_{i=1}^{m} (f_{w,b}(x^{(i)} - y^{(i)})^{2} $
- gradient descent algorithm
repeat until convergence {- $ w = w - \alpha \frac{\partial}{\partial w} J_{(w,b)} $
- $ b = b - \alpha \frac{\partial}{\partial b} J_{(w,b)} $
}
- where $ \frac{\partial}{\partial w} J_{(w,b)} $ = $ \frac{1}{m} \sum\limits_{i=1}^{m} (f_{w,b}(x^{(i)} - y^{(i)})x^{(i)} $
- and $ \frac{\partial}{\partial b} J_{(w,b)} $ = $ \frac{1}{m} \sum\limits_{i=1}^{m} (f_{w,b}(x^{(i)} - y^{(i)}) $

- We can simplify for
w
$$ \begin{align} \frac{\partial}{\partial w} J_{(w,b)} \ &= \frac{\partial}{\partial w} \frac{1}{2m} \sum\limits_{i=1}^{m} (f_{w,b}(x^{(i)} - y^{(i)})^2 \ &= \frac{\partial}{\partial w} \frac{1}{2m} \sum\limits_{i=1}^{m} (wx^{(i)} + b - y^{(i)})^2 \ &= \frac{1}{2m} \sum\limits_{i=1}^{m} (wx^{(i)} + b - y^{(i)}) 2x^{(i)} \ &= \frac{1}{m} \sum\limits_{i=1}^{m} (wx^{(i)} + b - y^{(i)}) x^{(i)} \ &= \frac{1}{m} \sum\limits_{i=1}^{m} ((f_{w,b}(x^{(i)}) - y^{(i)}) x^{(i)} \end{align} $$
- and for
b
$$ \begin{align} \frac{\partial}{\partial b} J_{(w,b)} \ &= \frac{\partial}{\partial b} \frac{1}{2m} \sum\limits_{i=1}^{m} (f_{w,b}(x^{(i)} - y^{(i)})^2 \ &= \frac{\partial}{\partial b} \frac{1}{2m} \sum\limits_{i=1}^{m} (wx^{(i)} + b - y^{(i)})^2 \ &= \frac{1}{2m} \sum\limits_{i=1}^{m} (wx^{(i)} + b - y^{(i)}) 2 \ &= \frac{1}{m} \sum\limits_{i=1}^{m} (wx^{(i)} + b - y^{(i)}) \ &= \frac{1}{m} \sum\limits_{i=1}^{m} ((f_{w,b}(x^{(i)}) - y^{(i)}) \end{align} $$



- a convex function will have a single global minimum
C1_W1_M3_6 Running gradient descent

- left is plot of the model
- right is contour plot of the cost function
- bottom is the surface plot of the cost function
- for this example,
w = -0.1, b = 900 - as we take each step we get closer to the global minimum
- the yellow line is the best line fit
- Given a house with
1250 sq ft, we can predict it should sell for$250k per the model

- Batch Gradient Descent => each step of the gradient descent uses all the training examples
- DeepLearning.AI newsletter: The Batch
Lab 04: Gradient descent
Quiz: Train the Model with Gradient Descent
- Gradient descent is an algorithm for finding values of parameters w and b that minimize the cost function J.
$$ \begin{aligned} \text{repeat until convergence {} \ &w = w - \alpha \frac{\partial}{\partial w} J_{(w,b)}\ &b = b - \alpha \frac{\partial}{\partial b} J_{(w,b)}\ } \end{aligned} $$
When $ \frac{\partial}{\partial w} J_{(w,b)} $ is a negative number, what happens to w after one update step?
- [ ] It is not possible to tell is
wwill increase or decrease - [ ] w increases
- [ ] w stays the same
- [ ] w decreases
- For linear regression, what is the update step for parameter b?
- [ ] $ b = b - \alpha \frac{1}{m} \sum\limits_{i=1}^{m} ((f_{w,b}(x^{(i)}) - y^{(i)}) $
- [ ] $ b = b - \alpha \frac{1}{m} \sum\limits_{i=1}^{m} ((f_{w,b}(x^{(i)}) - y^{(i)}) x^{(i)} $
Ans
2, 2C1_W2: Regression with Multiple Input Variables
This week, you'll extend linear regression to handle multiple input features.
You'll also learn some methods for improving your model's training and
performance, such as vectorization, feature scaling, feature engineering
and polynomial regression. At the end of the week, you'll get to practice
implementing linear regression in code.
C1_W2_M1 Multiple Linear Regression
C1_W2_M1_1 Multiple features

- $ \vec{x}^{(i)} $ = vector of 4 parameters for $ i^{th} $ row = $ [1416 3 2 40] $

- In this example, house price increase by (multiply 1k)
-
0.1per square foot -
4per bedroom -
10per floor -
-2per year old - add
80base price
-

- We can simplify the model
- From linear algebra, this is a row vector as opposed to column vector
- this is multiple linear regression
- Not multivariate regression
Quiz
In the training set below (see slide: C1_W2_M1_1 Multiple features), what is $ x_{1}^{(4)} $?
Ans
852C1_W2_M1_2 Vectorization part 1
Learning to write vectorized code allows you to take advantage of modern numberical linear algebra libraries, as well as maybe GPU hardware.

- Vector can be represented in Python as
np.array([1.0, 2.5, -3.3]) - if
nis large, this code (on left) is inefficient - for loop is more concise, but still not efficient
-
np.dot(w,x) + bis most efficient using vectorization - Vectorization has 2 benefits: concise and efficient
-
np.dotcan use parallel hardware
C1_W2_M1_3 Vectorization part 2
How does vectorized algorithm works...

- Without vectorization, we run calculations linearly
-
np.dotworks in multiple steps:- get values of the vectors
w, x - In parallel run
w[i] * x[i]
- get values of the vectors

C1_W2_Lab01: Python Numpy Vectorization
C1_W2_M1_4 Gradient descent for multiple linear regression


-
w & xare now vectors - have to update all the parameters simultaneously for $ w_{1} .. w_{n} $ as well as $ b $

- Normal Equation
C1_W2_Lab02: Muliple linear regression
Quiz: Multiple linear regression
- In the training set below, what is $ x_4^{(3)} $?
| Size | Rooms | Floors | Age | Price |
|---|---|---|---|---|
| 2104 | 5 | 1 | 45 | 460 |
| 1416 | 3 | 2 | 40 | 232 |
| 1534 | 3 | 2 | 30 | 315 |
| 852 | 2 | 1 | 36 | 178 |
- Which of the following are potential benefits of vectorization?
- [ ] It makes your code run faster
- [ ] It makes your code shorter
- [ ] It allows your code to run more easily on parallel compute hardware
- [ ] All of the above
- To make a gradient descent converge about twice as fast, a technique that almost always works is to double the learning rate $ alpha $
- [ ] True
- [ ] False
Ans
30, 4, FC1_W2_M2 Gradient Descent in Practice
C1_W2_M2_01 Feature scaling part 1

- Use Feature Scaling to enable gradient descent to run faster

- when we scatterplot size vs bedrooms, we see
xhas a much larger range thany - when we contour plot we see an oval
- ie small
w(size)has a large change & largew(bedroomshas a small change

- since contour is tall & skinny, gradeient descent may end up bounding back and forth for a long time
- a technique is to scale the data to get a more circular contour plot
![]() We can speed up gradient descent by scaling our features
We can speed up gradient descent by scaling our features
C1_W2_M2_02 Feature scaling part 2

- scale by dividing $ x_i^{(j)} / \max_x $

- Mean Normalization

- Z-score Normalization also called Gaussian Distribution

- When Feature Scaling we want to range somewhere between
-1 <==> 1 - but the range is ok if it's relatively close
- rescale if range is too large or too small
Quiz:
Which of the following is a valid step used during feature scaling? (see bedrooms vs size scatterplot)
- [ ] Multiply each value by the maximum value for that feature
- [ ] Divide each value by the maximum value for that feature
Ans
2C1_W2_M2_03 Checking gradient descent for convergence

- We can choose $ \alpha $

- Want to minimize cost function $ \min\limits_{\vec{w}, b} J(\vec{w}, b) $